Despite being trained only in simulation with a few task objects, our system demonstrates zero-shot transfer to a real-world robot equipped with a dexterous hand. These videos show building blocks into different shapes using our system in the real-world.
Abstract
Many real-world manipulation tasks consist of a series of subtasks that are significantly different from one another. Such long-horizon, complex tasks highlight the potential of dexterous hands, which possess adaptability and versatility, capable of seamlessly transitioning between different modes of functionality without the need for re-grasping or external tools. However, the challenges arise due to the high-dimensional action space of dexterous hand and complex compositional dynamics of the long-horizon tasks. We present Sequential Dexterity, a general system based on reinforcement learning (RL) that chains multiple dexterous policies for achieving long-horizon task goals. The core of the system is a transition feasibility function that progressively finetunes the sub-policies for enhancing chaining success rate, while also enables autonomous policy-switching for recovery from failures and bypassing redundant stages. Despite being trained only in simulation with a few task objects, our system demonstrates generalization capability to novel object shapes and is able to zero-shot transfer to a real-world robot equipped with a dexterous hand.
Method
(a). A bi-directional optimization scheme consists of a forward initialization process and a backward fine-tuning mechanism based on the transition feasibility function.
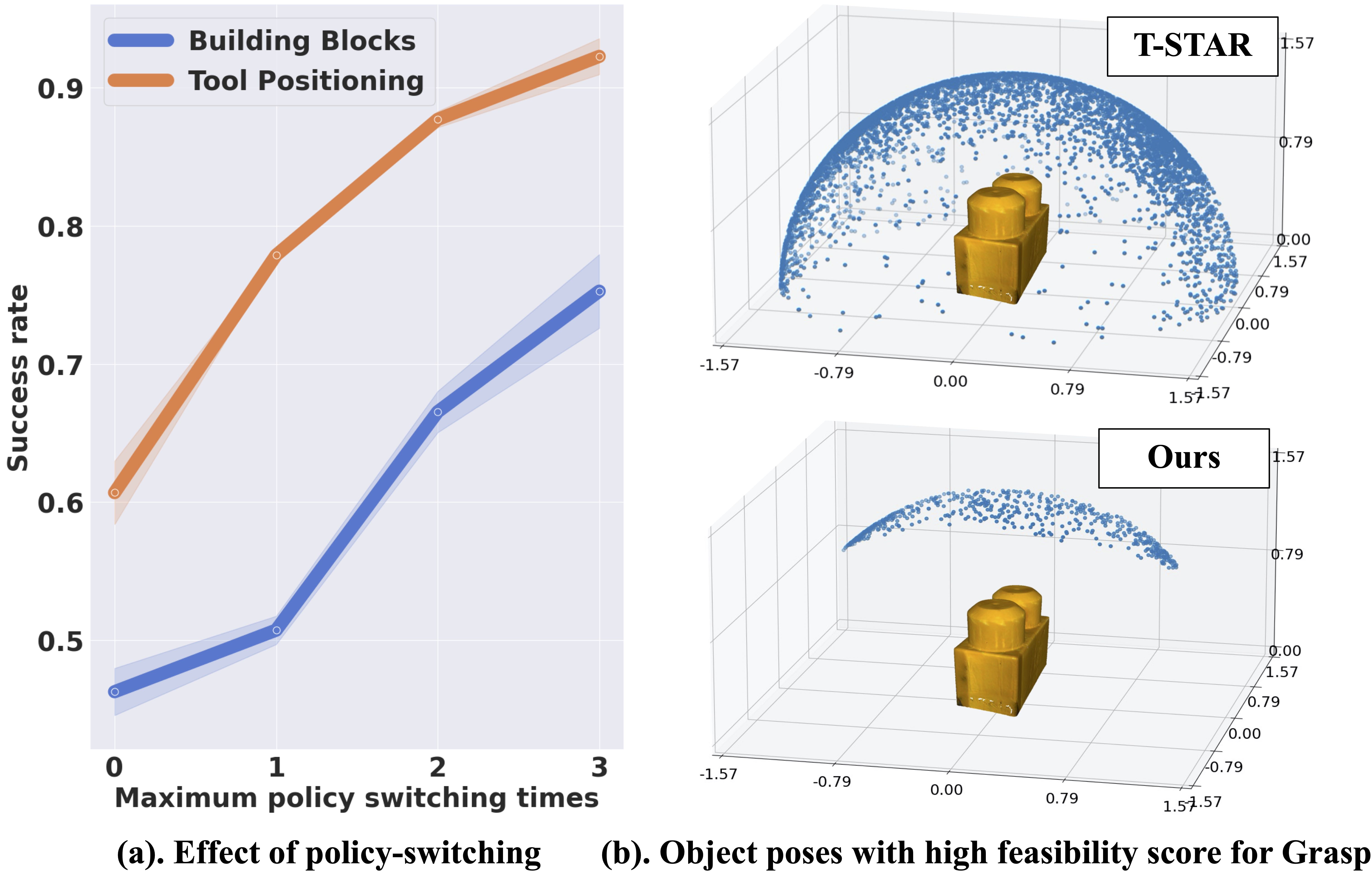
(b). The learned system is able to zero-shot transfer to the real world. The transition feasibility function serves as a policy-switching identifier to select the most appropriate policy to execute at each time step.
Experiments
Environment Setups
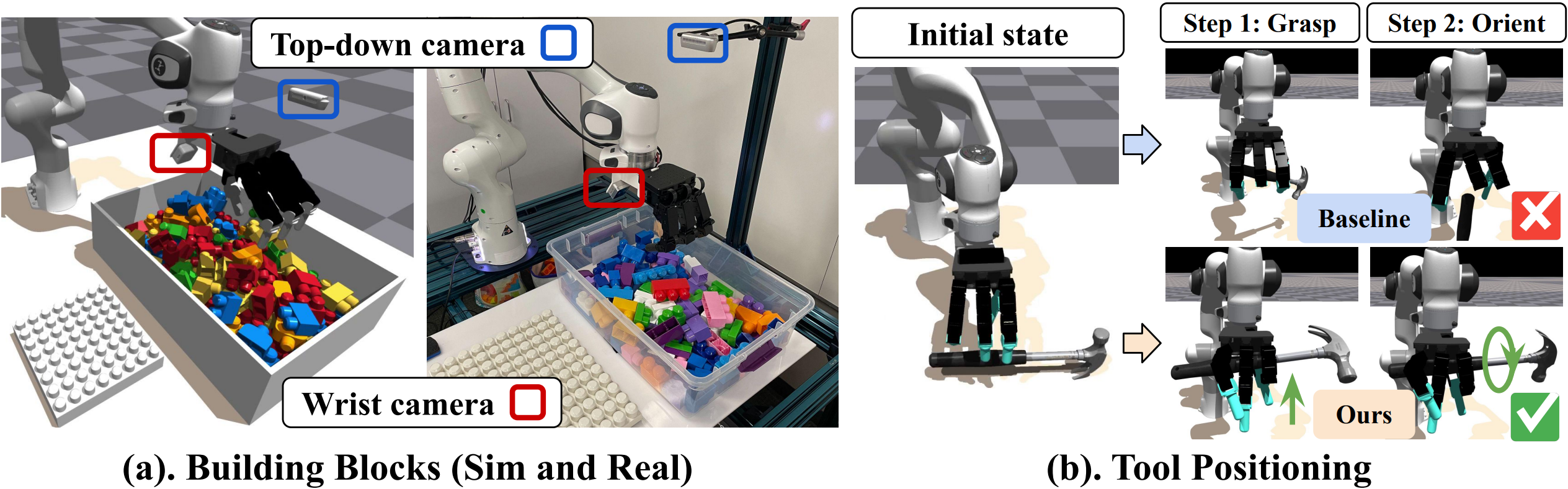
We test Sequential Dexterity in two environments:
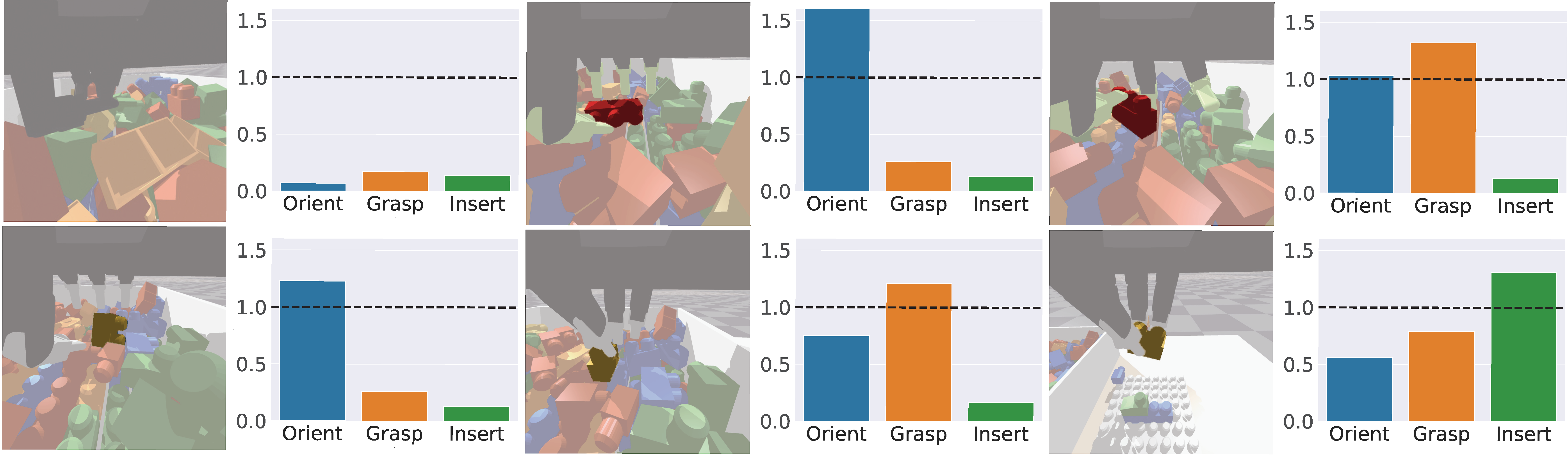
(a). Workspace of Building Blocks task in simulation and real-world. This long-horizon task includes four different subtasks: Searching for a block with desired dimension and color from a pile of cluttered blocks, Orienting the block to a favorable position, Grasping the block, and finally Inserting the block to its designated position on the structure. This sequence of actions repeats until the structure is completed according to the given assembly instructions.
(b). The setup of the Tool Positioning task. Initially, the tool is placed on the table in a random pose, and the dexterous hand needs to grasp the tool and re-orient it to a ready-to-use pose. The comparison results illustrate how the way of grasping directly influences subsequent orientation.
Learning sequential sub-policies in Isaac-Gym
Evaluation rollouts of the learned sub-policies
Evaluation rollouts of the chained policy sequence
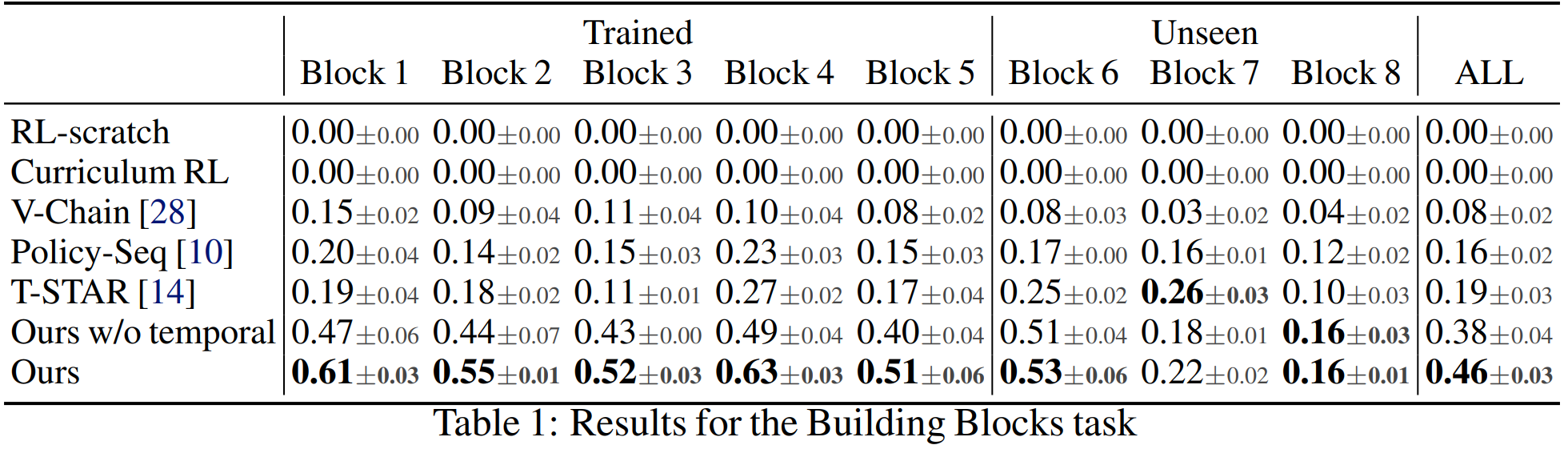
Building Blocks task
Since it is impossible to simulate the contact-rich insertion of blocks in simulation, the insertion skill in sim is a simplified version and the robot learns to use finger jittering to place the block. In the real-world experiments, we only perform the insertion policy when the hand is still in the air (in-hand rotate and align to the goal location). The moving down and pressing motion used to fully insert the block is scripted.
Tool Positioning task
Hammer - Ours
Spatula (Unseen) - Policy-Seq [10]
Spatula (Unseen) - Ours
Spoon (Unseen) - Policy-Seq [10]
Spoon (Unseen) - Ours
Interactive GUI
Feel free to try out our quick demo (Interactive GUI)! To get the best performance for this demo, the policy takes the full state information (object acceleration, motor velocity, …) as inputs and is allowed to control the end-effector orientation, which is the policy before distillation for the real-world deployment.